

Как использовать Numpy и Pandas для анализа ценовых данных
Вся нужная база с примерами по двум популярным библиотекам.
NumPy: ускоряем числовой анализ
NumPy — библиотека для быстрых математических операций над массивами. Она работает на C, что делает её молниеносной по сравнению с обычными Python-списками. Именно NumPy лежит в основе большинства библиотек: Pandas, Scikit-Learn, TensorFlow, PyTorch — все они используют NumPy под капотом.
Почему NumPy крут:
- Скорость: массивы NumPy работают на C, что делает операции в десятки раз быстрее, чем с обычными Python-списками.
- Память: NumPy массивы более компактны и оптимизированы.
- Функциональность: широкий набор функций для статистики, агрегации, обработки временных рядов и линейной алгебры.
- Совместимость: большинство библиотек (Pandas, Scikit-Learn, TensorFlow) используют NumPy под капотом.
Импорт и базовая структура
import numpy as np
Создадим массив из цен закрытия BTC:
prices = np.array([13410.03, 13570.35, 13220.56, 13247.0, 13240.37])
1. Основные свойства массива
print(prices.shape) # размерность (5,)
print(prices.dtype) # тип данных (float64)
print(prices.ndim) # количество осей (1)
2. Арифметика с массивами
NumPy поддерживает векторные операции (без циклов!):
# Рост на 5%
increased = prices * 1.05
# Разница между соседними значениями (доходность)
returns = np.diff(prices)
3. Статистический анализ
print(np.mean(prices)) # средняя цена
print(np.std(prices)) # стандартное отклонение
print(np.min(prices)) # минимум
print(np.max(prices)) # максимум
print(np.median(prices)) # медиана
Эти методы полезны для оценки волатильности и определения границ канала.
4. Скользящие окна (MA)
Скользящая средняя — один из ключевых элементов технического анализа. С помощью np.convolve можно легко ее реализовать:
def moving_average(data, window):
return np.convolve(data, np.ones(window)/window, mode='valid')
ma = moving_average(prices, 3)
print(ma)
5. Условные выборки и фильтрация
# Фильтруем цены выше 13300
high_prices = prices[prices > 13300]
Или создаем логические маски:
mask = prices > np.mean(prices)
above_avg = prices[mask]
6. Прогнозирование наивной моделью
# Наивный прогноз: следующий шаг = предыдущий
predicted = np.roll(prices, 1)
predicted[0] = predicted[1] # корректируем первую точку
# Ошибка прогноза
mae = np.mean(np.abs(prices - predicted))
print(f'MAE: {mae:.2f}')
7. Работа с 2D-массивами (OHLC)
Рассмотрим пример массива OHLC:
ohlc = np.array([
[13715.65, 13715.65, 13155.38, 13410.03],
[13434.98, 13818.55, 13322.15, 13570.35],
[13569.98, 13735.24, 13001.13, 13220.56],
])
highs = ohlc[:, 1]
lows = ohlc[:, 2]
ranges = highs - lows
Практика: волатильность как индикатор
# Волатильность как относительный диапазон свечи
volatility = (highs - lows) / ohlc[:, 3]
print(volatility)
Визуализация
import plotly.graph_objects as go
import numpy as np
# Данные
prices = np.array([13410.03, 13570.35, 13220.56, 13247.00, 13240.37, 13380.00, 13353.78])
dates = pd.date_range(start='2023-01-01', periods=len(prices), freq='4H')
def moving_average(data, window):
return np.convolve(data, np.ones(window)/window, mode='valid')
ma = moving_average(prices, 3)
# Обрезаем даты под длину скользящей средней
ma_dates = dates[len(dates) - len(ma):]
# График
fig = go.Figure()
fig.add_trace(go.Scatter(x=dates, y=prices, mode='lines+markers', name='Цена', line=dict(color='black')))
fig.add_trace(go.Scatter(x=ma_dates, y=ma, mode='lines', name='MA(3)', line=dict(dash='dot')))
fig.update_layout(
title='Цены и скользящая средняя (NumPy + Plotly)',
xaxis_title='Время',
yaxis_title='Цена',
template='plotly_white',
hovermode='x unified'
)
fig.show()
NumPy — это не просто библиотека, а основа числового анализа в Python. Без неё не было бы ни Pandas, ни SciPy, ни TensorFlow, ни Scikit-learn.
Если вы трейдер, аналитик или дата-сайентист, то NumPy — ваш первый шаг в мир высокопроизводительных вычислений.
Вот почему NumPy так важен:
- Ускоряет вычисления: операции происходят векторно, без циклов, с C-подкапотом.
- Упрощает работу с массивами: фильтрация, агрегация, работа с окнами — всё компактно и быстро.
- Готовит почву для продвинутого анализа: без NumPy невозможно строить ML-модели, симуляции и стратегии.
Pandas: инструмент №1 для анализа рыночных данных
Если NumPy — это «математика под капотом», то Pandas — это то, с чем вы работаете руками. Эта библиотека создана специально для табличных и временных данных, таких как свечи, объемы, сигналы и индикаторы. Именно Pandas используется в 90% случаев при анализе рыночной информации и лежит в основе большинства аналитических пайплайнов в Python.
Что делает Pandas незаменимым:
- DataFrame — структура, идеально подходящая для хранения OHLCV-данных.
- Удобная обработка: фильтрация, группировка, ресемплинг, агрегации, скользящие окна.
- Работа со временем: таймстемпы, временные индексы, преобразование частот.
- Гибкая интеграция: дружит с NumPy, Plotly, sklearn, API и базами данных
Установка библиотеки
pip install pandas plotly
Шаг 1. Загрузка и предварительная обработка данных
import pandas as pd
# Загрузка CSV-файла (например, исторические данные по BTC)
df = pd.read_csv('btc_data.csv')
# Конвертация времени и установка индекса
df['Open time'] = pd.to_datetime(df['Open time'])
df.set_index('Open time', inplace=True)
# Оставим только нужные столбцы
df = df[['Open', 'High', 'Low', 'Close', 'Volume']]
df = df.sort_index()
print(df.head())
Шаг 2. Анализ цен: скользящие средние и возвраты
# Скользящие средние
df['ma_5'] = df['Close'].rolling(window=5).mean()
df['ma_20'] = df['Close'].rolling(window=20).mean()
# Доходность
df['returns'] = df['Close'].pct_change()
# Оценка волатильности
df['volatility'] = df['returns'].rolling(window=10).std()
Шаг 3. Визуализация с Plotly
import plotly.graph_objects as go
fig = go.Figure()
# Цена
fig.add_trace(go.Scatter(x=df.index, y=df['Close'], name='Цена', line=dict(color='black')))
# MA
fig.add_trace(go.Scatter(x=df.index, y=df['ma_5'], name='MA 5', line=dict(dash='dot')))
fig.add_trace(go.Scatter(x=df.index, y=df['ma_20'], name='MA 20', line=dict(dash='dot')))
fig.update_layout(
title='Цены и скользящие средние (Pandas + Plotly)',
xaxis_title='Время',
yaxis_title='Цена',
template='plotly_white',
hovermode='x unified'
)
fig.show()
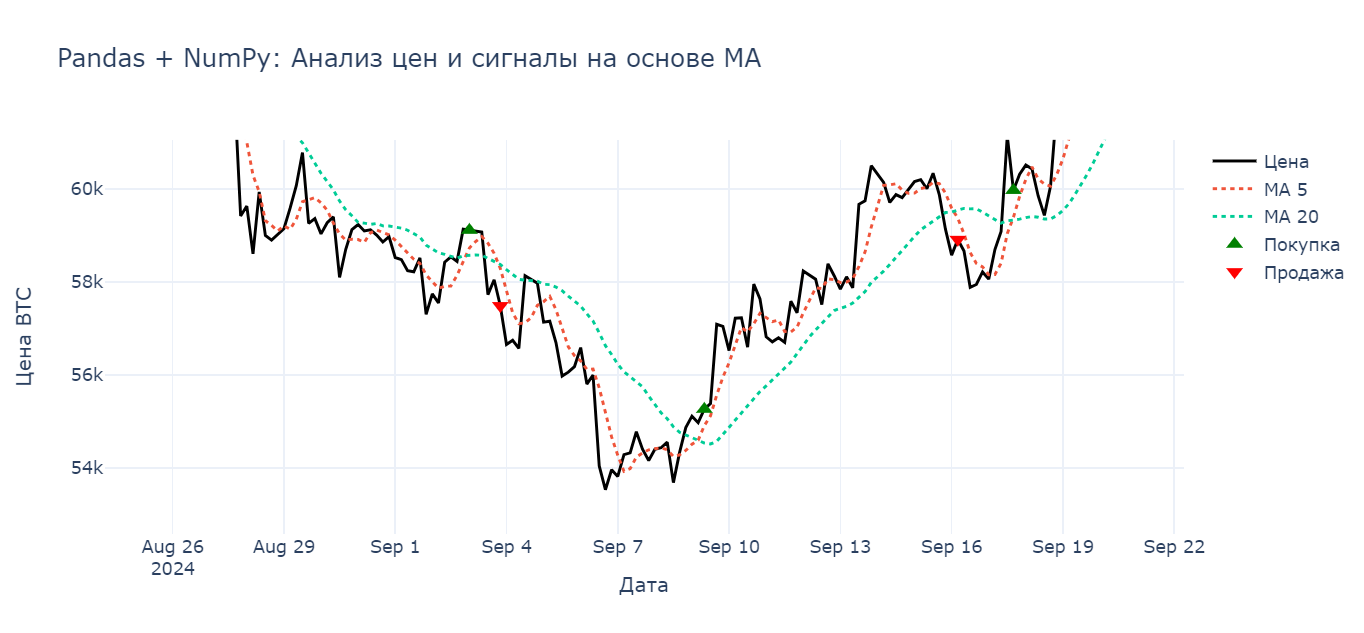
Шаг 4. Простой сигнал на основе MA
# Сигнал: MA5 пересекает MA20 снизу вверх = покупка
df['signal'] = 0
df['signal'] = df['ma_5'] > df['ma_20']
df['position'] = df['signal'].diff()
Визуализация сигналов:
buy = df[df['position'] == 1]
sell = df[df['position'] == -1]
fig = go.Figure()
fig.add_trace(go.Scatter(x=df.index, y=df['Close'], name='Цена', line=dict(color='black')))
fig.add_trace(go.Scatter(x=buy.index, y=buy['Close'], name='Покупка', mode='markers',
marker=dict(color='green', symbol='triangle-up', size=10)))
fig.add_trace(go.Scatter(x=sell.index, y=sell['Close'], name='Продажа', mode='markers',
marker=dict(color='red', symbol='triangle-down', size=10)))
fig.update_layout(title='Сигналы на основе пересечения MA (Pandas + Plotly)', template='plotly_white')
fig.show()
Шаг 5. Дополнительные возможности Pandas
Фильтрация
# Все свечи с объемом больше среднего
high_volume = df[df['Volume'] > df['Volume'].mean()]
Агрегация
# Среднее закрытие по дням
daily_mean = df['Close'].resample('D').mean()
Группировка
# Средняя волатильность по неделям
weekly_vol = df['volatility'].resample('W').mean()
Вывод
Pandas — это универсальный инструмент анализа рыночных данных, и вот почему:
- Он превращает сырые CSV-файлы в структурированные DataFrame.
- Позволяет строить сигналы и стратегии без сложных зависимостей.
- Является основой большинства аналитических и торговых пайплайнов.
Если вы планируете анализировать данные с биржи, запускать бэктесты, подключать API — вы будете использовать Pandas в 90% случаев.
Pandas и NumPy — основа анализа данных в трейдинге
Если вы всерьёз решили заняться анализом рыночных данных, бэктестингом или построением торговых стратегий — начните с NumPy и Pandas. Это не просто библиотеки — это базовые инструменты, без которых не обходится ни один аналитический пайплайн в трейдинге.
NumPy — это мотор высокопроизводительных вычислений:
- Векторные операции без циклов,
- Быстрая статистика и агрегаты,
- Работа с массивами цен, объёмов, доходностей и индикаторов.
Pandas — это универсальный инструмент для работы с табличными и временными данными:
- DataFrame — структура, в которой удобно мыслить трейдеру,
- Скользящие окна, группировки, фильтрации,
- Прямое взаимодействие с CSV, API и визуализациями.
Эти библиотеки не конкурируют — они работают вместе:
- NumPy лежит в основе Pandas, обеспечивая скорость и гибкость;
- Pandas — обёртка, которая делает данные удобными для анализа.
Освоив их, вы получите уверенный фундамент, на котором можно строить всё: от простых сигналов и индикаторов до ML-моделей и комплексных фреймворков.
Код и примеры вы, как всегда, найдёте в нашем репозитории. Подписывайтесь на профиль и не забудьте поставить ⭐ репозиторию

